1. 소개
딥러닝 이전의 TTS는 SPSS(Statistical Parametric Speech Synthesis)의 기술이 사용되었다. 간단히 설명하자면
Text -> Text Analysis -> Acoustic Model -> Vocoder로 이루어진 모델이다.
Text Analysis에서 언어적 특성을 추출
Acoustic Model에서 음향학적 특성을 추출
Vocoder에서 음향학적 특성을 오디오로 바꿔준다.
** HMM 모델이 Acoustic Model로 주로 사용되었음 **
아무튼 딥러닝 기술의 발전으로 성능 좋은 신경망 TTS가 나오게 되었다. 이러한 End to End TTS시스템은 다양한 이점이 있다.
1. 전문지식이 필요한 엔지니어링을 완화
2. 다양한 속성을 조절하기 쉬움(감정, 화자, 언어 등등)
3. 새로운 데이터 적용 쉬움
4. End to End의 하나로 이루어진 모델이 더 robust함
Seq2Seq Attenion이 주요 모델로 떠오르고 문자와 소리는 같은 시퀀스 데이터임을 착안하여 스피치에 적용한 모델이 Tacotron임
2. Model
Backbone model은 Attention이다. 전체적인 구조는 Encoder, Decoder, Post-processing net으로 이루어져 있다.
input은 character,@@@ output은 spectrogram이며 waveform으로 변환된다. @@@@ post processing에서 바뀌는 건지 확인하고 수정하기@@@

2.1 CBHG module

1-D convolution bank + highway network + bidirecitional GRU로 이루어진 모듈이다. 시퀀스에서 representation을 추출하는 역할을 한다.
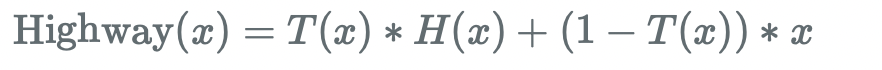
highway network는 residual과 비슷하지만 residual의 비율을 모델이 선택할 수 있도록 구성되어 있다.
1. input으로 k개 set의 1D convolution filter가 들어오고 1D convolution 수행.
-> contextual 정보를 모델링하는 과정
2. Conv1D bank를 통과한 output들은 stack하고 max pooling을 수행한다.
-> local invariance를 증가 // 원래 시간 resolution을 보존하기 위해 stride는 1을 사용
3. conv1D 연산을 수행
-> 결과는 원래 input과 residual connection 수행, batch norm 모든 conv1D에서 사용
4. highway layer 수행
-> high level의 feature를 추출
5. bidirectional GRU
CBHG 베이스 모델은 기존 multi layer RNN에 비해 오버피팅을 줄여주고 적은 오발음(mispronunciation)을 만든다
2.2 Encoder
Encoder의 목적은 robust한 sequential representation을 추출하는 것
input으로 character 시퀀스가 들어감. 각 character는 원핫백터의 형태.
-> continuous vector로 임베딩되고 각각의 임베딩에 pre net이라는 non-linear transformations이 적용
pre net -> 드랍아웃을 포함한 bottle neck 레이어를 사용 (256 -> 128)
-> 이것은 convergence와 generalization 향상에 도움을 줌
CBHG은 prenet의 아웃풋을 attenrtion에 들어갈 representation으로 변환
2.3 Decoder
content-based tanh attention decoder가 사용된다.
context vector와 attention RNN cell의 output을 concat해서 decoder RNN의 input으로 만든다.
vertical residual connection을 사용한 GRU들을 디코더로 사용했다.
-> residual connection이 수렴의 속도를 올려줌
80-band mel-scale spectrogram을 예측한다.
-> 더 낮은 band나 간결한 target도 사용가능함
seq2seq의 target은 충분한 정보와 음율 정보를 충분히 가질만큼 압축된다.
간단한 fully-connected output layer을 decoder target으로 decoder의 target을 내는데 여기서 중요한 트릭이 사용된다.
target이 한번에 mel spectrogram을 하나씩 예측하는것이 아닌 r개씩 예측하는데 음성신호는 여러개의 연속적인 프레임(서로 관련되어 있고 같은 수치가 연속되는 경우도 많음)으로 구성되기 때문에 유의미한 가정이다.
-> 이 트릭은 모델의 수렴과 학습속도를 올려준다
2.4 Post-processing network
seq2seq target을 waveform으로 바꿔준다.
Griffin-Lim을 사용했다.
Reference
[논문리뷰]Tacotron https://joungheekim.github.io/2020/09/25/paper-review/
[논문리뷰] Tacotron: Towards End-to-End Speech Synthesis (INTERSPEECH17) https://music-audio-ai.tistory.com/24
'AI > 논문' 카테고리의 다른 글
| VAE: Auto-Encoding Variational Bayes (0) | 2023.03.06 |
|---|---|
| [논문 리뷰] Wavenet: A GENERATIVE MODEL FOR RAW AUDIO (0) | 2023.02.26 |
| [논문 리뷰] Automated Music Generation for Visual Art through Emotion (0) | 2023.02.20 |
| Transformer (0) | 2022.02.12 |
| NLP - Efficient Estimation of Word Representations in Vector Space(Word2Vec) (0) | 2022.02.04 |



