[논문 리뷰] Wavenet: A GENERATIVE MODEL FOR RAW AUDIO
Wavenet 논문을 읽던 중 몇가지가 이해가 안됐었다.
1. 모델이 학습되는 구조 Residual block 과정에서 블럭별로 일정한 차원(512)의 output이 계속해서 다음 블럭으로 전달되고 skip connection으로 나오는데 DILATED CAUSAL CONVOLUTIONS에서 차원이 일정하게 유지될 수 가 없는것 같고 설령 유지되더라도 아래의 DILATED CAUSAL CONVOLUTIONS figure 처럼 받지 못할 것 같았다(feature가 뒤섞이거나 할거같았음).
추론- 코드를 봤더니 512차원이 유지되는것은 dilate가 늘어날때마다 패딩을 맞춰줘서 늘어나는것이었다. (dilate =512 일때는 패딩이 꽤 많이 늘어나는데 패딩이 늘어나도 학습에 상관이 없는것인가 모르겠다 ..) 그림 때문에 학습방식이 어떻게 되는지 이해가 안됐었는데 패딩이 늘어나서 512차원을 유지시키고 다양한 dilate로 (1, 2, 4, 8 ,,, 512, 1, 2, 4, 8 ,,,, 512)의 layer를 쌓으며 다양한 범위를 학습시켜서 학습에 도움이 되는것인가 싶다..
512차원은 채널이었습니다...
2. output값을 현재시점의 input으로 추가하며 학습을 한다고 이해했는데 기존에 있던 input값은 이전 acoustic model에서 나온 feature고 output으로 나오는 값은 waveform인데 그대로 이어붙여서 학습해도 큰 문제가 없는것인지??
(waveform이라는 긴 시퀀스를 output으로 내야하는데 그러면 기존 acoustic feature를 순차대로 다학습하게 된다면 output으로 나온 waveform들로만 학습이 되는것인지)
- 추론 아직 모르겠움
autoregressive니까.. 당연히 괜찮고 문제없음 문장 생성 task랑 큰 차이없는데 왜 햇갈렸을까?..
3. 1x1 conv 사용 이유
- 추론 채널수를 유지시키며 레이어를 쌓기 위해 그런듯하다(1x1 conv 포스트 -> https://yonghiiiii.tistory.com/25)
4. GATED ACTIVATION UNITS을 보면 tanh와 시그모이드로 같은 x가 들어가는줄 알았는데 DILATED CAUSAL CONVOLUTIONS output을 반으로 split후 각각 conv 레이어 통과후 tanh와 시그모이드로 들어가고 각 output을 element wise 곱 후 conv로 512차원을 맞춰준다. (논문에서는 실험에서 rectified linear activation function보다 잘 작동했다고 한다.)
여기서 반으로 나눠서 들어가는게 어떤 의미가 있는지 ?
-추론 GATED ACTIVATION UNITS 찾아봐야할듯

conditional probability distribution - x1부터 xt-1 까지의 요소들로 xt를 예측한다.
이러한 형태는 convolution layer를 쌓아서 형성되며 pooling layer가 없다.
마지막 output은 softmax연산을 통해 classification이 되어 xt를 구하게 된다.
DILATED CAUSAL CONVOLUTIONS

Dilated convolution와 Causal convolution을 섞은 것이다.
Dilated convolution은 필터의 간격을 넓혀 수용범위(Receptive Field)를 넓히는 방법이다. 수용범위가 커지니 적은 layer를 쌓아도(적은 계산량으로) 넓은 수용범위를 가질수 있다.
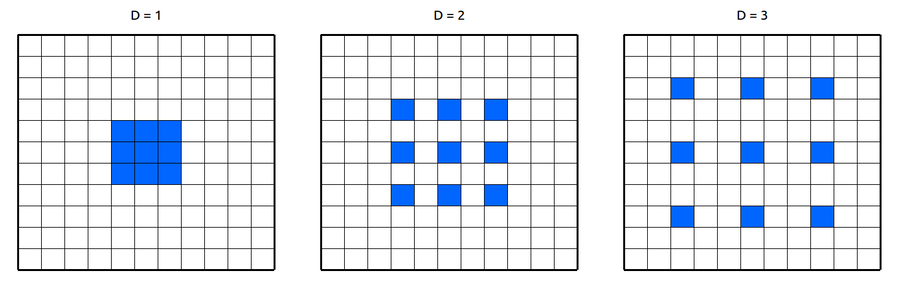
Causal convolution은 시간 순서를 고려하는 방법이다. 이전 시점들의 정보만 가지고 현재 시점을 예측한다. 그렇게 때문에 시퀀셜한 데이터를 다룰수 있게 만들어주는 방법이다.
이러한 두가지 방법으로 long-range temporal dependency한 특성을 가지는 audio data를 다룰수 있게 해준다.
GATED ACTIVATION UNITS

Dilated 이후 tanh와 시그모이드로 나눠지는 부분이 GATED ACTIVATION UNITS이다.
pixel cnn에서 고안한 방식이라 하고 local feature를 filter 다음 layer에 얼마나 전해줄지를 정하는데 gate라는데
tanh가 filter 시그모이드(0부터 1의 퍼센티지를 계산)가 gate역할을 한다.
이러한 계산을 통과후 element wise 곱을 수행후 cnn에 들어간다.
궁금한점 - 왜 dilated conv의 output을 반으로 split해서 들어갔는지이다. 뭔가 정보를 강제적으로 반으로 나눠서 각각 다른 역할을주고 다른 함수에 넣는것이 이해가 잘 되지 않는다. pixel cnn 논문을 참조해야할것같다.
RESIDUAL AND SKIP CONNECTIONS
많은 모델에서 쓰이는 방법임. 필요하지 않은 Layer를 skip할 수 있는 역할을 하며 좀더 심층적으로 layer를 쌓게 해주고 속도를 올려주는 역할을 한다.
Conditional Modeling
Wavenet은 condition을 줘서 특정 음성을 생성할 수 있다. 간단한 예로 text 정보를 input으로 조건을 주게 되면 text 음성을 생성한다
Global Conditional, Local Conditional이 있음
Global Conditional

특정 화자 음성을 생성하고 싶은 경우
-> 이는 시점별로 변하는 정보가 아니다 -> 모든 시점에 condition을 줘야함
condition을 필터와 게이트 부분에 추가함으로써 영향을 준다.
Local Conditional

TTS의 경우 Text embedding을 조건으로 줘야하지만 text는 audio에 비해 상대적으로 짧다. 이를 잘 alignment 시켜줘야하는데
Text embedding과 같은 condition을 upsampling을 통해 audio feature의 길이와 맞춰주는 방법을 사용해야한다 .
개인적인생각
논문을 보며 학습과 추론이 어떤 방식으로 되는지 순차적으로 생각해 봤는데 잘 이해가 되지 않아 몇주간 힘들었다. 아무래도 논문에서 제시한 DILATED CAUSAL CONVOLUTIONS fig와 실제 코드 구현이 달라서 그랬던것같다. 코드를 뜯어서 보니 어느정도 이해가 되었고 (궁금한점이 더 늘기도 했지만..) 성능좋은 유명한 vocoder 모델이고 많은 파생 모델을 낸 모델이기 때문에 방법론들을 다른 모델에 적용 혹은 개인 프로젝트를 할때 이용할 수 있도록 더욱 잘 이해하려고 했다. 오디오와 같이 기본적으로 긴 시퀀스를 다루기 위해서 사용된 여러 방법론들을 잘 배웠다.