Music VAE
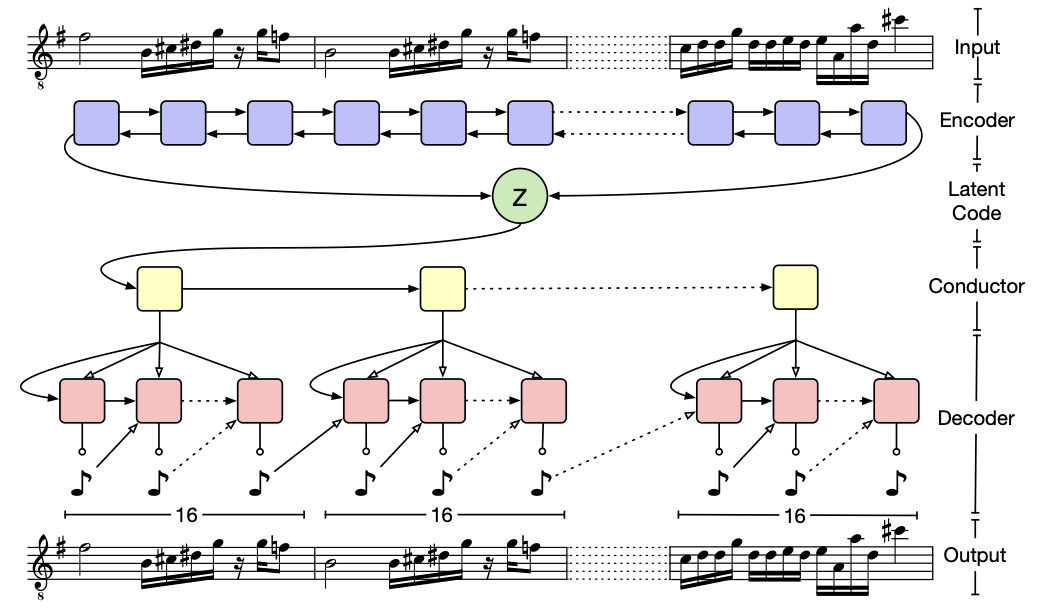
Model
Bidirectional Encoder
two-layer bidirectional LSTM network를 encoder로 사용
두번째 bidirectional LSTM layer에서 각 방향의 hidden state vector를 얻는다
얻은 vector 두개를 concat 후 two fully connected layer를 통과해 μ and σ를 뽑아낸다.
2048의 lstm stare size
512의 latent vector size
Hierarchical Decoder
이전 recurrent VAE decoder에서는 간단한 rnn layer를 쌓아서 사용했지만 본 논문에서 긴 시퀀스를 샘플링이 잘 안된다는것을 실험을 통해서 알아냈다.
-> vanishing influence of the latent state as output sequence is generated라고 나와 있는데 이건 Posterior Collapse문제라고 한다
*Posterior Collapse
Decoder가 latent z를 무시해서 encoder의 condition을 배제하고 생성하는 현상KL term이 0이 되서 local optima에 빠지는 것이라는데
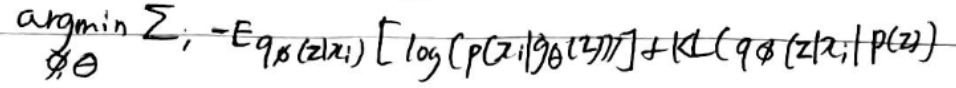
위 식에서 KL텀이 0이되고 Generator만 maximum likelihood 한다는 말인듯하다.
발생이유
1. Decoder가 latent z 없이 과거 데이터로만 생성 가능한 경우 **그래서 긴 시퀀스 데이터에서 발생하나? **
2. 조건에 맞는 다양한 latent z가 존재할때 **그래서 VAE에서 regularization 텀이 있는게 아닌가?**
3. z가 시퀀스 전체의 속성을 못담고 다음 step 예측에만 사용될때 (MLE에 집중)
4. encoder가 z를 잘 표현 못할때
5. 가정한 가우시안 prior에 아무 정보가 없음
### 참고 - https://stopspoon.tistory.com/63
이 문제를 해결하기 위해 novel hierarchical RNN을 사용
latent z -> fully-connected layer + tanh -> conductor Rnn의 시작 state vector
conductor Rnn은 U embedding vector C를 만듦
conductor Rnn = two-layer unidirectional LSTM , state size = 1024, 512

각 c를 생성하면 shared fully conndected layer + tanh를 통과 -> 마지막 decoder Rnn의 시작 state vector
decoder Rnn은 output 생성 -> softmax
decoder RNN에서 각 output이 나오면 현재 계산하고 있는 cu와 이전 output을 concat해서 input으로 넣어준다.
decoder RNN = 2-layer LSTM, 각 LSTM의 layer는 1024 unit을 가짐
@@@ posterior collapse를 해결하기 위해
long term structure를 위해 decoder의 범위를 제한해서 latent를 강제적으로 사용하게 해야한다.
cnn에서는 receptive field를 줄이면 되지만 RNN은 기본적으로 제한이 없는 receptive field를 가지고 있기에
bottom-level decoder( 최종 output을 생성하는)의 유효 범위를 줄였다 -> output subsequence 내에서만 전파하도록 함
RNN의 시작을 conductor에서 내려오는 임베딩으로 각 subsequence RNN state를 초기화.
-> conductor 임베딩을 concat해서 사용했다는 말인듯
Music VAE에 사용된 방법중 중점이 되는 부분은 아무래도 hierarchical RNN과 conducter의 임베딩을 다음 input step에 같이 넣어줌으로 latent vector의 영향력을 키운것이라고 생각이든다.
본 논문에서는 posterior collapse를 해결하기 위해서 넣어줬지만 만약 posterior collapse 문제가 없었다면 음악 생성에서 RNN과 hierarchical RNN의 성능차이는 어떻게 될까?
hierarchical RNN은 부분부분을 학습해서 연결하는 역할을 하는데 본 논문처럼 한 계층위의 임베딩 정보를 concat해서 넣어주는 방식이 긴 시퀀스인 음악도메인에서 이전 정보를 잃어버리지 않고 잘 생성하는 역할을 하게 되는것인가
SAMPLERNN
Hierarchical Recurrent Neural Networks for Conditional Melody Generation with Long-term Structure
논문을 참고해보자
##