[논문 리뷰] VQ-VAE Neural Discrete Representation Learning
Intro
기존 VAE는 prior을 가우시안으로 가정, encoder에서 평균, 분산을 뽑아내 latent z를 연속적인 값으로 만들었다.
VQ-VAE에서는 encoder를 통과한 값을 vector quantization을 사용해서 latent z를 discrete하게 만들었고 prior을 categorical으로 가정. 또한 VQ 방법으로 Posterior Collapse 문제를 해결했다고 밝히고 있다.
*Posterior Collapse란
Decoder가 latent z를 무시해서 encoder의 condition을 배제하고 생성하는 현상KL term이 0이 되서 local optima에 빠지는 것이라는데

위 식에서 KL텀이 0이되고 Generator만 maximum likelihood 한다는 말인듯하다.
발생이유
1. Decoder가 latent z 없이 과거 데이터로만 생성 가능한 경우
2. 조건에 맞는 다양한 latent z가 존재할때
3. z가 시퀀스 전체의 속성을 못담고 다음 step 예측에만 사용될때
4. encoder가 z를 잘 표현 못할때
5. 가정한 가우시안 prior에 아무 정보가 없음
Model

Latent vector를 이산 표현으로 다룬다.
-> posterior과 prior distribution이 categorical distribution임
이 분포로부터 생성된 sample이 embedding table을 indexing한다.
-> encoder로 부터 나온 vector가 Embedding space(코드북)에서 가장 가까운 vector(L2 norm)의 index 값을 가지게 되고 이는 z(그림의 파란박스)에 들어간다.
Embedding space(코드북) - K*D 크기의 벡터
K - discrete latent space 크기(code word 개수)
D - 각 codeword의 차원
posterior categorical distribution q(z|x)의 확률은 크기 K의 one hot encoding으로 정의


학습방법
임베딩 스페이스와 z 부분은 gradient가 흐를수없다.
-> 디코더(zq)와 인코더(ze)를 이어붙여서 gradient를 바로 인코더로 보낸다. (zq와 ze의 dimension이 같아서 가능함)
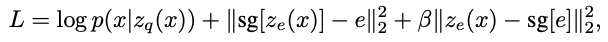
첫번째 항 reconstruction loss - encoder, decoder 학습
-> 임베딩 스페이스, latent z부분에 gradient가 흐를수 없기에 디코더의 input에서 encoder output으로 gradient를 copy한다.
두번째 항 Codebook loss - 코드북을 훈련하는 항,
-> encoder에서 나온 e를 ze와 비슷해지도록 업데이트하는 원핫을 구하는 과정에 해당, 간단한 dictionary learning 알고리즘을 사용해서 L2거리 error 값을 줄이도록 학습한다.
**sg - 스탑그래디언트 - 인코더 값을 고정시키고 그 출력값으로부터 e를 학습
세번째 항 Commitment loss - 인코더 학습과 코드북학습이 병렬적으로 안됨 , 딕셔너리로부터 인코더를 학습하는것을 보완
-> ei는 encoder만큼 빠르게 학습 힘들고 임의로 커질수 있음
##codeword가 많아서 항상 update되는 encoder에 비해 학습이 더디고 encoder와 개별적으로 학습되서 커질수있다는 말인듯?
-> 그래서 encoder vector가 embedding vector와 유사해지도록 만들어줌
## Codebook loss에서 개별적으로 코드북만 학습하는 단방향이 아닌 commitment loss를 추가해서 역전파 학습을 함으로 양방향 학습으로 연관성을 추가해 속도와 크기를 맞추는 효과인듯?
prior
prior를 categorical distribution으로 가정 z에 대해 autoregressive하게 만들어짐(generation 할때)
학습할때는 uniform distribution으로 가정 -> KLD가 상수값으로 됨 -> 그레디언트 계산할때 사라짐
후기
latent vector를 VQ로 이산적이게 만든점, 이러한 구조를 학습하기 위해 decoder와 encoder를 이어서 학습시키는것도 신기하고 처음보는 방법론이라 인상깊게 보았다.
encoder -> 코드북 -> latent -> decoder로 넘어가는 부분이 어떻게 넘어가는지 잘 상상이 안되는데 코드를 하나씩 살펴보며 공부해봐야겠다. 또 audio에 어떻게 적용할 수 있을지 컴퓨터 리소스가 많이 필요할지 공부해야겠다~~
참고
VQ-VAE paper https://proceedings.neurips.cc/paper/2017/file/7a98af17e63a0ac09ce2e96d03992fbc-Paper.pdf